




All your data, connected, clean, and ready to use
We map every data source in your organisation — databases, SaaS tools, spreadsheets, and APIs — to understand what you have, where it lives, and how it currently flows.
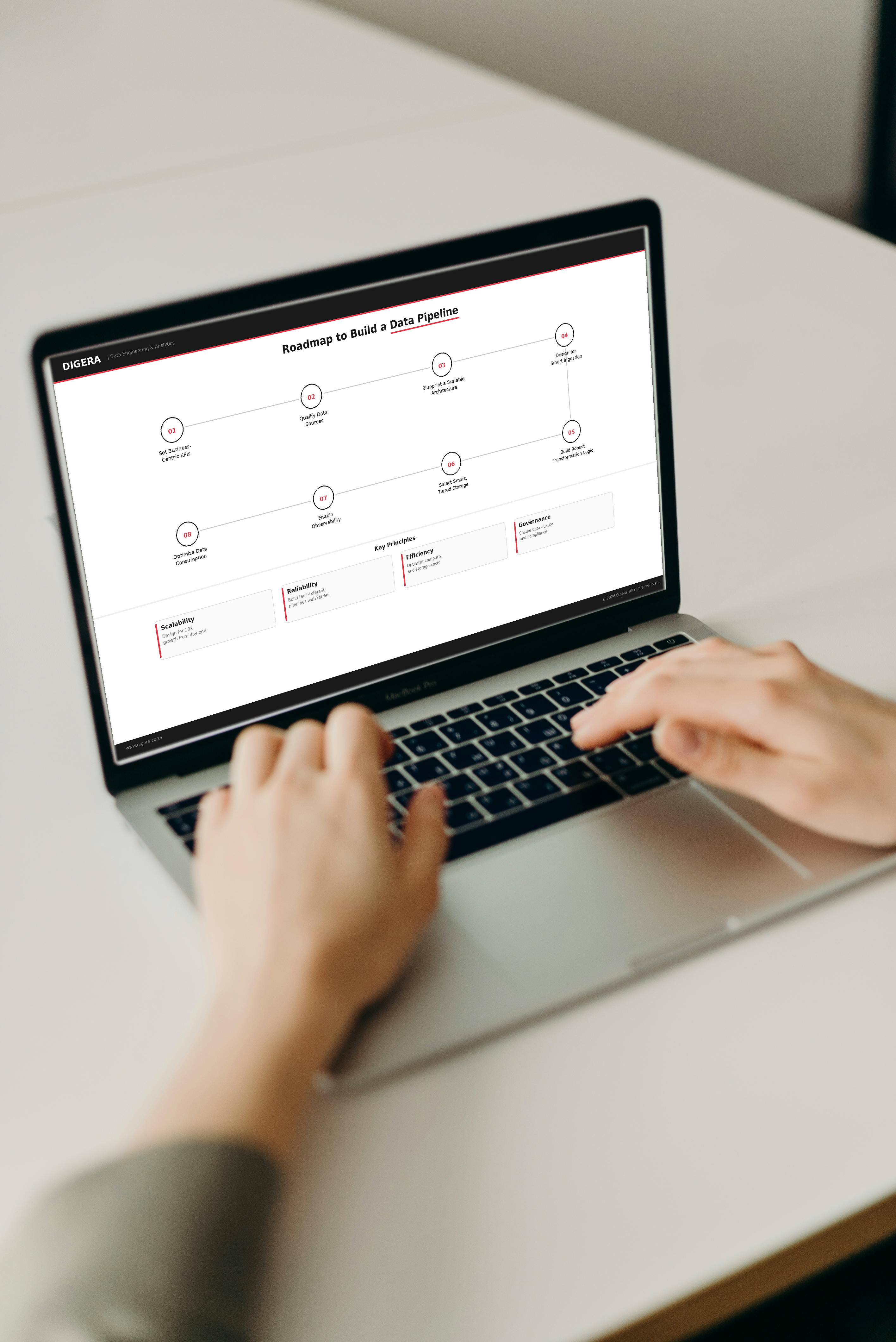
We design a scalable data pipeline architecture that ingests, transforms, and delivers your data reliably — built for your volume today and ready to grow with you tomorrow.
We build and deploy your Extract, Transform, Load pipelines — handling data cleansing, deduplication, schema normalisation, and scheduling so your data arrives clean every time.
We configure and optimise your data warehouse — whether that's BigQuery, Snowflake, Redshift, or another platform — so your teams can query and analyse with speed and confidence.
We implement automated data quality checks and alerting so your team is notified the moment something breaks, drifts, or arrives late — before it affects your decisions.
Data pipelines need maintenance as your sources and schema evolve. We offer ongoing support to keep your pipelines healthy, fast, and aligned with your changing data landscape.
What We've Been Building
We built a Python-based extraction pipeline using Claude API, PyMuPDF, and Google Vision OCR that processed 1,700 documents in under 100 minutes — saving over 425 hours of manual work.